



博彩问答 3D鸟类重建—数据集、模型以及从单视图恢复形状

项目链接:https://marcbadger.github.io/avian-mesh
论文链接:https://www.ecva.net/papers/eccv_2020/papers_ECCV/papers/123630001.pdf
作者:Longway
概述
动物姿态的自动捕捉正在改变研究神经科学和社会行为的方式。运动携带着重要的社会线索,但是现有的方法不能很好地估计动物的姿态和形状,特别是鸟类,会受到环境中的物体遮挡。为了解决这个问题,作者首先引入了一种模型和多视图优化方法,来捕捉鸟类独特的形状和姿势空间。然后介绍了一种用于从单视图准确恢复鸟类姿势的方法,还包括鸟类的关键点、mask和外形。最后提供了一个包含大量多视图关键点和mask注释的鸟类数据集,可以从上面的项目链接中找到。
简介
1、为什么计算动物行为学?行为的准确测量对于神经科学、生物力学、人类健康和农业至关重要。通过自动测量,计算行为学旨在捕捉姿势、方向和位置方面的复杂变化,其中姿势包含丰富的信息,我们可以从中提取出更多与大脑功能、生物力学和健康相关的抽象特征,同时在自然社会行为下研究神经功能是深入理解大脑如何整合感知、认知、学习和记忆来产生行为的关键一步。

视觉信号传达了鸟类重要的社交信息2、为什么鸟类的姿势很重要?为什么是燕八哥?了解社会群体的集体行为是如何从个体互动中产生的,对于研究社会行为背后的社会性进化和神经机制非常重要的。虽然声音是鸟类交流的重要渠道,但是姿势、方向和位置的变化也在交流中扮演着十分重要的作用。从行为学和神经科学的角度来看,最好的研究群体之一是褐头燕八哥。在燕八鸟中,雌性通过一系列视觉机制影响雄性的行为,例如“翼击(wingstrokes)”,这包括随着时间的推移姿势和形状的变化。
3、为什么估计鸟的姿势和形状很有挑战性?主要有四个原因,姿势和形状的变化很难在鸟类身上建模、没有姿势和形状的先验知识可用、许多鸟只能从一个无遮挡的视角看到和自然环境下的外观变化使检测变得困难。

不同鸟类、不同视点、不同时间和不同季节的外观变化4、数据集。为了建立一个稳健的系统来估计多个相互作用的鸟类在长达数月的时间尺度上的形状和姿势,作者记录了15只燕八哥在三个月的交配季节里一起住在户外鸟舍里的行为。这个多视图数据集包含鸟类姿势、方向和位置/深度的巨大变化,通过八个摄像头记录了不同光照条件和季节的外观。

数据集和模型作者在为1000个实例标注轮廓和关键点后,使用基于多视图优化的方法来拟合鸟类网格模型,以学习形状空间和姿态先验知识。然后利用模型和先验知识训练神经网络,直接从关键点和轮廓数据回归姿态参数。这些姿态参数可以用来初始化一个单视图优化程序,以进一步细化身体姿态和形状。

从一个角度估计鸟类的三维姿态和形状总的来说,这篇论文的主要贡献如下:
开发了第一个参数化的鸟类网格模型,能够捕捉鸟类特有的姿态和形状变化。使用基于优化的方法将网格模型与多视点关键点和轮廓数据相匹配,以获得精确的形状空间和姿势先验。开发了一种基于神经网络的模型,用于从单一视图恢复鸟类的形状和姿态。提供了一个多视角数据集来研究鸟类的社会行为。相关工作
人体姿势和形状的估计:最近在人体姿态估计方面已经利用了强大的2D联合检测器、3D姿态先验以及低维的人体关节三维形状模型。SMPL是现在最流行的方案,首先使用从超过1000个扫描体中学到的形状和姿态参数变形一个模板网格,然后使用线性混合蒙皮(LBS)对给定的一组关节角的网格顶点进行变换。当然还有一些比较出名的算法,比如SMPLify。
现在很多方法都是基于参数化网格模型,这表明了它们在连接二维观测和三维估算之间的至关重要的作用。与之前的工作依赖于3D扫描和类似 SMPL的模型来开发网格和形状空间不同的是,作者直接从活鸟的视频数据中学习鸟类网格模型。
动物姿势和形状的估计:在生物学中,大部分的工作都是集中在单独的动物,没有杂乱的背景和少数的遮挡。很多学者都做了与此相关的工作,比如说Liu等使用HOG描述符和线性支持向量机在更具挑战性的CUB-200-2011数据集中定位鸟类部位【1】,这些工作都是基于检测和2D关键点的直接三角测量。但是一个基本的挑战是,任何特定的关键点可能不能从一个视图可见。限制关键点相对位置的模型,如前面提到的参数化网格模型,克服了这个问题。
动物的形状估计也是一个困难的任务。也有许多学者做了大量工作,其中比较有名的是Kanazawa等人,他们通过创建动物特有的局部刚度模型来了解动物如何从图像中变形【2】。另外,通过变形球形网格来预测CUB-200中鸟类的形状、姿态和纹理,但没有对姿态进行建模,因此在拓扑结构上,翼尖在网格上的位置通常与尾巴相邻,而不是靠近肩部。
还有大量工作是关于SMPL模型的,但是该模型仅在四条腿的动物上训练,因此模型学习到的形状空间不足以用于建模鸟类,因为鸟类在四肢形状和关节角度上都有显著差异。为了克服鸟类统计模型的不足,作者在每个关节增加了一个额外的自由度,从多视角获得适合活鸟的姿态和形状空间。
动物姿态估计的数据集:相比于MS COCO、CUB-200等数据集,该多视图数据集包含多个重叠物体的mask和关键点,并且在相对的视点上有很大的变化,背景和光照也有复杂的变化。
方法
作者开发的模型训练过程如下,实现了从单个图像进行鸟类三维重建。首先,开发了一个参数化的鸟类网格,并使用一个多视图优化程序来适应数据集中的注释模型。其次,从多视图拟合中,作者提取鸟类的形状和姿势分布,使用它来创建一个合成数据集,在这个数据集上训练神经网络,从单个视图中的关键点和轮廓回归姿势和形状参数。第三,训练第二个网络来预测实例分割和关键点。最后,将关键点和分割网络连接到姿态回归网络。整个流水线提供了来自单个视图的姿态和形状估计,可用于进一步的优化。
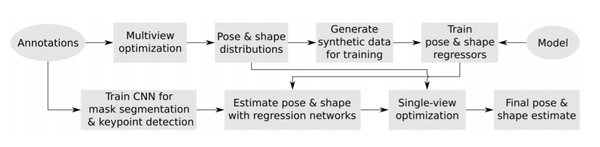
从单一视图恢复鸟类姿势和形状的整体方法
完整图像中的鸟类检测:使用预先训练过的用于COCO实例分割的Mask R-CNN来检测鸟类,并且移除没有鸟类的实例,只剩下鸟类和背景。
关键点和轮廓预测:训练一个卷积神经网络来预测关键点和轮廓,给出一个检测和相应的包围框,同时修改了高分辨率网络(HRNet)【4】的结构,它是目前最先进的人体关键点定位技术,除了关键点,还可以输出mask。
线性关节鸟类模型:为了定义一个初始网格、关节位置和权重,作者使用了一个鸟类模型的三维网格。这个模型原本有18k个顶点和13k个面,但是作者移除了很多与细节相关的点,以获得一个有3932个顶点、5684个面和25个骨骼关节的网格。
为了设置模型姿势,作者提出了一个骨骼长度参数的函数M(α,θ,γ,σ),其中α表示J个关节点,θ表示关节点的相对旋转,鸟舍内的整体平移γ和比例σ,返回一个有3932个顶点的网格。
当鸟类栖息时,它们的翅膀会折叠在自己身上,这种巨大的变形并不能很好地用单一鸟类网格模型来模拟。为了解决这个限制,作者使用了两种模板姿势,它们有着相同的网格拓扑结构、骨骼、权重和关键点,但它们的初始姿势不同:一个是伸展翅膀的鸟,另一个是折叠翅膀的鸟,如下图所示。

模型能够捕捉栖息和飞行时的姿势
为了形成给定姿势的网格,作者修改了SMPL【5】和SMPLify【6】中使用的方法以允许不同的骨骼长度。从具有关节位置J的标准姿势中的模板网格M开始,首先计算每个关节i相对于父节点的位置
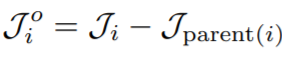
然后用这个向量乘以αi来调整两个关节点之间的距离,形成一个新的骨骼形状J’

其中A (i)是节点i的祖先节点的有序集合。最后,使用全局刚性变换Rθ(▪)将J’=J(α)转换成最后的姿势,其中R函数由位姿和根方向参数θ定义,并且应用了线性混合蒙皮LBS函数W。最后的网格顶点如下
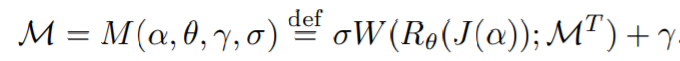
优化:为了使鸟模型适合于检测到的关键点,作者引入了一个类似于SMPLify【6】的拟合过程,不同的是,使用骨骼长度参数而不是身体形状参数来捕获个体差异,和语义关键点相对应而不是关节位置。最小化一个目标函数,包括每个摄像机i的关键点重投影误差项和轮廓误差项,两个姿势先验以及关节之间的相对三维距离的先验,如下所示:
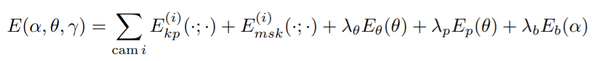
其中
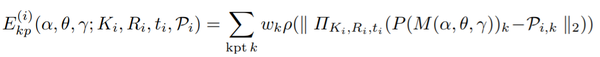
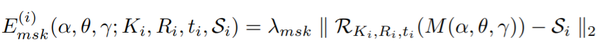
合成数据和位姿与形状回归:在标注的数据集中对140个3D鸟类实例进行多视图优化后,作者拟合一个多元高斯估计的姿态参数(位姿、视角和平移)。然后,从每个鸟类实例的分布中随机抽取100个点,将相应模型的可见关键点投射到相机上并渲染轮廓,生成14,000个合成实例用于训练。保留原始的140个实例的骨骼长度,但在每个样本的骨骼长度上添加了随机噪声。对于位姿回归网络,输入为二维关键点 ,目标为三维的旋转参数,网络主体结构是多层感知机MLP。
实验结果

基于多视图优化的鸟类网格模型对关键点和mask标注的拟合,上面部分是好的案例,下面是失败的案例

从单一视角恢复鸟类的姿势和形状【1】Wah, C., Branson, S., Welinder, P., Perona, P., Belongie, S.: The Caltech-UCSD Birds-200-2011 Dataset. Tech. Rep. CNS-TR-2011-001, California Institute of Technology (2011)
【2】Kanazawa, A., Kovalsky, S., Basri, R., Jacobs, D.: Learning 3D deformation of animals from 2D images. Computer Graphics Forum 35(2), 365–374 (2016). https://doi.org/10.1111/cgf.12838, https://onlinelibrary.wiley.com/doi/abs/10.1111/cgf.12838
【3】Kanazawa, A., Tulsiani, S., Efros, A.A., Malik, J.: Learning category-specific mesh reconstruction from image collections. In: ECCV (2018)
【4】Sun, K., Xiao, B., Liu, D., Wang, J.: Deep high-resolution representation learning for human pose estimation. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 5686–5696 (2019)
【5】Loper, M., Mahmood, N., Romero, J., Pons-Moll, G., Black, M.J.: SMPL: Askinned multi-person linear model. ACM Trans. Graphics (Proc. SIGGRAPH Asia) 34(6), 248:1–248:16 (Oct 2015)
【6】Bogo, F., Kanazawa, A., Lassner, C., Gehler, P., Romero, J., Black, M.J.: Keep it SMPL: Automatic estimation of 3D human pose and shape from a single image. In: Computer Vision – ECCV 2016. pp. 561–578. Lecture Notes in Computer Science, Springer International Publishing (Oct 2016)
第二个技巧:理牌动作要有节奏。主要就是理牌的速度要快,千万不要一时快,一时慢,有时候慢上一秒,就代表你少观察牌势一秒。多思考一秒博彩问答,从容的可以更从容博彩问答,紧迫的也能够放松下来!
上一篇:真人龙虎游戏 预算低的学生党要怎么入坑手冲咖啡(特别是磨豆设备和手冲壶) 下一篇:龙虎斗游戏 ROHS认证收费标准ROHS认证流程




