



阿里天池第一届PolarDB数据库性能大赛补遗(一)-谈文件系统对快存储IO性能的影响

本文不打算涉及比赛的具体技术方案,一来对于没有研究过赛题的人来说,只是看个热闹,收获其实有限。更进一步,不同的人基于不同的目的参加比赛,点评赛题本身往往会引出争议。为了不带来困扰,补遗系列仅仅关注笔者在大赛中的若干有趣思考及实践,它以大赛作为背景,但具体论及的内容本质上在大赛之外、之上。
然而,本文作为笔者复(硬)出(广)计划的开篇之作,在最后依然会对阿里天池系列工程赛事有所感怀。
# 文件系统的对IO性能的影响
最后的结论是,文件系统对快存储的IO性能有显著影响。
## 4k随机写入被废
作为数据中心存储现阶段的王者,Optane固态硬盘形态的这块P4800x,其”王“既不在峰值带宽(其峰值在当前高端SSD中已经比较low),也不太是低队列深度下的4K通量(多数服务器端场景的队列深度并不是问题),而是其超低延迟(但受制于PCIe总线以及现代主控中DRAM缓存的使用,其表现较之于高端SSD也只能算是好一些,谈不上特别惊艳)和超高稳定性(其实企业级SSD都还稳定)。
另一个"王",笔者认为是,4K随机IO和4K顺序IO的性能高度一致。闪存,作为固态硬盘的代称,其小块下(4K)随机IO和顺序IO往往(相对)差别较大,因两者在其底层材料上的迥异。而这一差别将颠覆现有存储引擎设计中的一些基本观念。所以,笔者特别感兴趣在此之上是否有些工作。
在使用fio进行测量时,笔者发现按评测的流程,每次清空数据后,4K随机写入的通量/IOPS在开始的十几秒(该dstat运行设定每3秒采样一次)过后出现严重下滑。看看相关dstat数据:
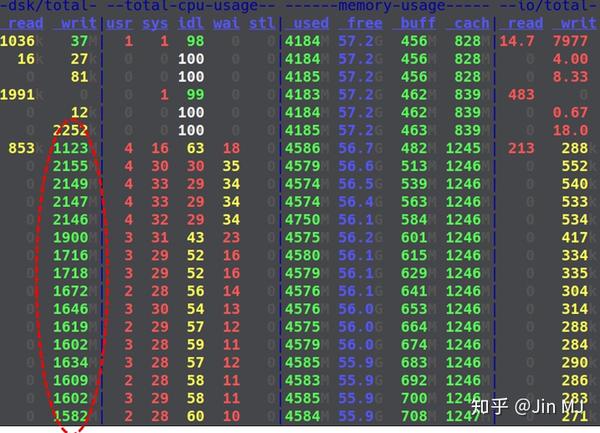
而如果不清空数据文件,看上去符合预期的应该是这样:
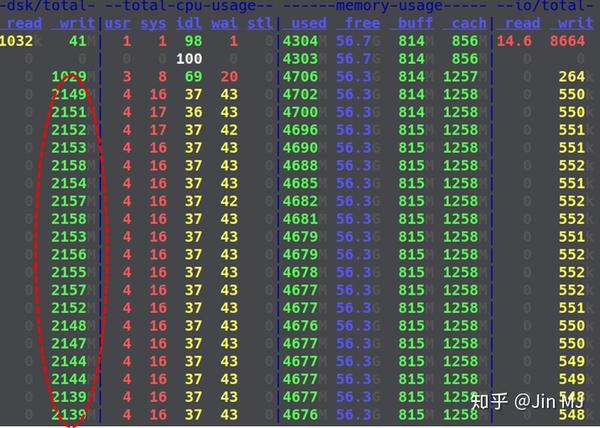
观察到过该现象的同学应该不少,比如[这篇博文](http://kernelmaker.github.io/nvme_ssd_fio)(恰巧,该博文的作者是阿里云polardb团队的一员,负责本次赛事的具体组织)。但尚未(发现)有人分析过其中的原因。
清空数据何惧?预分配啊?fio没调用fallocate?fio作为Linux环境下IO测试的标准工具,自然不会犯这样的低级错误(fallocate是fio默认配置,比赛中有参赛者谈及posix_fallocate vs fallocate的问题,其实在现代linux发行版上这两个函数的行为应该一样的,如果不一样,参赛者代码写错的可能性更大)。那么差别这么大的根本原因是什么?
回答这个问题,我们需要:科学的测量。
(题外话:回答这类问题并不会提高比赛排名,甚至显然“浪费时间”。所以,暴力尝试各种方案依然是广大同学打比赛乃至在工作实践中所使用的主要方法。勇于试错没有问题,但不应只停留在这个层面。笔者一直倡导的是,科学的测量。从benchmark到measurement,体现了一名工程师能否把工程实践推向极致的考量。)
下图对有无降速两种情况下的运行时基本信息及热点进行了对比:
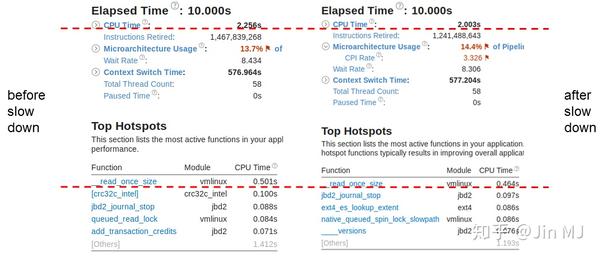
左边为未发生降速时的一个10s运行时采样,而右边为发生降速时的一个10s采样。总体上,两者差别不明显。
未发生降速时CPU Time(cpu工作时间,CPU is actively executing your application)略长,此时写入快一些正符合预期(cpu干了更多事)。但需要进一步找到cpu工作时间产生差异的原因。移步下方检查运行时间top5的函数信息,可以发现决定性差距就在top1的__read_once_size。
但因为都是__read_once_size,需要深入运行栈。

明显可以发现,重大差异体现在从上图运行栈的红色划线部分。到这里,已经有必要深入kernel源代码了,道听途说、ctrl+c/v都是bad idea。这里__read_once_size干什么不太重要,但笔者希望各位看官自己调研一下__read_once_size是干什么的,很多kernel调用栈的终点都是它,可见其地址之基础。(同时可以顺带了解下kernel基本编码规范)
__read_once_size调用主要都来自native_queued_spin_lock_slowpath,但它的上游却很不一样。未降速时的主要工作时间基本在pv_queued_spin_lock_slowpath,而降速后时,上游排第一的调用ren一样的(__versions只是展示上不同),但排第二的调用发生在一个含有jdb2_journal_dirty_metadata的链条上,从耗时及其占比来看,“案子”的线索出来了。
进一步向上展开上述两条调用栈:

从划红线的函数调用附近开始,左右两条调用栈开始有所不同。
从函数名可以得知:右边降速情况下ext4文件系统更新元数据相当耗时。但到这里,我们还不能解释:“为什么fallocate不起作用?”
要解释这个,我们需要搞清楚调用链上这些函数名字中所涉及的概念:
* spin_lock: kernel常用的线程间同步机制。
* block: 存储介质上的物理存储单位。
* map_blocks
* extent: 对于一个大的文件,会占用很多(特别是连续的)block,一个个枚举出来浪费内存,所以kernel文件系统的开发者添加了一层抽象-extent,来表示一段连续的blocks。
* split_extent:extent的维护基于树状结构(btree),所以操作它会需要在extent tree的节点上做split。
* unwritten_extents: fallocated的block并不会真的allocated,而是进入一个unwritten的状态。
* delalloc: Delayed Allocation的缩写,关心性能的文件系统想出一个”延迟分配“extents的方法,以期来改善extent tree上分配节点的性能(比如减少文件系统的碎片)。显然unwritten是一种delalloc,但反之则不尽然。
到此,“为什么fallocate不起作用”的原因也就清楚:fallocate并没有真的让ext4分配(allocate)blocks给文件,而只是将其标记为unwritten状态,这些被延迟分配的unwritten的extents/blocks都需要在最后写的时候分配出来。降速发生时(jbd2)并发分配中的dirty元数据操作中的spin_lock消耗了相当的CPU Time;而速度正常时,因不清空上次测试的文件,不需要分配extents/blocks及其相关的dirty元数据操作,也就没有这一部分开销。
“案子”破了。顺带,对ext4文件系统的基本概念有清晰的认识。更进一步,不限于ext4,内核里几个高性能文件系统在其设计和实现上其实有很多共性,所以我们对内核文件系统的基本面也有了了解。
# 点评
所以,想要完全利用快存储,你可能需要绕过文件系统。更进一步的发挥,超过了本文讨论的范围。
笔者在此更想要强调的是:把一件事情做好那就一定要深入。想要把文件系统的问题搞清楚,分析内核里的调用链是必须的。
```
要分析内核?“这可能不行吧?这能做到吗?然而当自己真正努力去做了,它反而并没有想象中的那么难,有很多不擅长的东西也不是完全不能做到。”
```
# 理想中的工程赛事
利用业余时间打比赛,如果赛制不能支撑老司机们“四两拨千斤”的优势,则依然较大程度上是一个体力活。
一直以来,笔者问自己的两个问题:
1. 坚持参加比赛,为了什么?
其实笔者一直都期待,比赛能够聚拢一些醉心于(性能)工程实践的小伙伴。工程类比赛,其实一直是一个很特殊的存在。大家经常看到两类赛事:编程类算法比赛(Google Code Jam类)和数据类算法比赛(kaggle、天池等)。而面向所有人参与的工程向赛事,做起来的只有阿里天池。
不过比较遗憾的是,到目前为止没有特别让笔者眼前一亮的小伙伴(除了第三届比赛笔者认识的一位中科院计算所/国科大博士师弟)。小伙伴们所展现的动力导向主要还是赛题和排名,而很少有其外的东西。当然比赛中依然有不少有潜力的同学,他们能在一些细节上比其他选手走的更远,不少已经被阿里招入麾下。但须知,知识性的细节只是low-hanging fruit,是否有工程向的创新是笔者更喜好的(评价标准)。
2. 如果是笔者来办这样一个比赛,会怎么办?
之前的系列赛其实有不少硬伤。窃以为最大的一个硬伤是,工程系列赛一直没有借鉴数据赛的最佳实践:测试数据集和验证数据集相分离。
公开比赛的最大特点是,“大浪淘沙”。能不能淘到真金,我们不只能靠价值观,我们需要一个机制。当我们使用可dump的同一数据集来确定最终排名时,这对工程向赛事的打击是毁灭性的。更有甚者,某次赛事允许“适当的利用数据的规律”,助长了投机风气,最终只能是“劣币驱逐良币”。诚然,数据是公开的,这对所有人都平等。但诸如,dump大量测试消息发现其只用了ascii字符,所以可以从8bits压缩为6bits;或者是通过大量尝试发现测试key/value只使用了200个汉字,所以可以从3bytes压缩到1byte。难道这种“低级”技巧是我们通过一次全球公开比赛想要发掘的东西?比赛的时间毕竟是有限的,如果“低级”技巧大行其道,意味着比赛质量也会很“低级”。
如果有机会,笔者想办一个这样的工程向比赛:
1. 赛题完全来自现实的开源项目需求(但语言上还是需要考虑受众面);
2. 赛题测试kit开源(保留对比赛中测试数据产生逻辑等进行修改的权利),任何人可以提交改进PR;
3. 比赛排名分为公榜和私榜,公榜开放出来供所有人调测,可轻量dump任意数据,私榜只出成绩且只对本人(及评委会)可看,私榜服务器和公榜服务器隔离,一天可只运行一次;
4. 测试数据集产生未必一定“随机”,但具有一般性(比如来自生产数据),同时故意特化公榜数据(WTF?);
5. 赛程为半年左右“马拉松”,评委会成员自己亦参与比赛和排名(但无获奖资格),每月一次“月旦评”阶段性奖励私榜排名靠前的选手(由评委会评出票选,宁缺毋滥);
6. 最后一个月为终评,本月的私榜成绩计入最终成绩排名,最终记分采用得分的期望和方差加权计算;
7. 最后一个星期,排名截止并开源所有参赛方案,同时邀请参赛者学习和点评;
8. 评委会基于排名和众评结果,票选出最后的获奖名单,并公开理由,宁缺毋滥;
9. 最后的颁奖活动来个大party(可以和社区活动结合^_^)......
# 再见,阿里天池
从阿里天池第二届中间件大赛(第一次允许所有人参赛)到本次第一届PolarDB数据库大赛,笔者或多或少都参与其中,在此期间和阿里的许多同学都有过交集,深深感受到了阿里人的技术热情,平衡商业和技术是件很难的事情,为阿里人在工程领域的成果感到骄傲。
而笔者“休息”数年后,亦认为到了一个合适的时间点重回开源社区:
1. 作为工具的Rust语言,比去年这个时候要成熟很多。
2. 作为方向的数据基础设施,在开源上的发展差强人意。笔者认为,微创新我们是有了,但能不能拿出让世界点赞的开源数据基础设施?中国的工程师们还在路上......
# 推荐阅读
该PPT力求平易近人,适合没有参加比赛的同学以及对比赛没有兴趣的同学,其中包含很多基础数据和前沿话题,总结和讨论了存储系统层级中一些有方向意义的设计和实现思路,具有前瞻性和原创性,从其中摘一二十个本硕士课题和引申三五博士课题,都是很easy的。
内核文件系统的“弱点”,在现场答辩PPT里其实涉及了2处,而本文只涉及一处。本文从总决赛结束就开始动笔,但因为“总是比较繁忙”,两个月竟未成篇,逐决定拆分出来。另一处是什么?
欢迎有兴趣的小伙伴们发掘和联系笔者:)
欢迎大家引用和扩展相关结果,欢迎关注本系列后续更新。
------
[1] https://tianchi.aliyun.com/competition/entrance/231689/introduction
打麻将技巧之规则的掌握与驾驭是核心也是重点,熟悉了基本的规则之后,再选择找更好的方法。胡牌的目标也是技巧性,因为胡牌的不同方式赌博平台,结账的方法也不相同,只有保证胡得更大,才能收获更多,单纯追求胡牌的次数,不需要技巧,就是新手学习的方法,而高手一定在意胡牌的大小。
打麻将技巧还有一个上看好上家,上家给自己的打牌,是可以就近利用有最大好处的赌博平台,如果正好在抉择胡哪张牌的时候,看看上家不需要什么牌,这样就会有更多的胡牌机会,如果和上家要一样的牌,就会减少胡牌的机会,这也是麻将打法中的大忌,和别家要一样的牌,影响胡牌率,就得靠手气,如果不是逼不得已,最好别做这样的选择。
上一篇:博彩问答 20212027年全球与中国锂离子电池绕线机行业产销需求与投资预测分析报告 下一篇:比氮化镓更香10款手机实测倍思SuperSi超级硅充电头




