



博彩问答 干货PPOCR35M超轻量中英文OCR模型详解(一)简介、方案概览和数据

论文地址:https://arxiv.org/abs/2009.09941
代码地址:https://github.com/PaddlePaddle/PaddleOCR
一、简介
PP-OCR是一个实用的超轻量中英文OCR系统,是针对中英文OCR问题,对最新的文本检测算法 Differentiable Binarization (DB) 和经典的文本识别算法CRNN的能力充分挖掘,虽然没有理论创新,但是从骨干网络选择和调整、预测头部的设计、数据增强、学习率变换策略、正则化参数选择、预训练模型使用以及模型自动裁剪量化8个方面,采用19个有效策略,对各个模块的模型进行效果调优和瘦身,最终得到整体大小为3.5M的超轻量中英文OCR和2.8M的英文数字OCR,下面是一些识别效果图。


二、PP-OCR概览
下图是PP-OCR的流程图,主要由DB文本检测、检测框矫正和CRNN文本识别三部分组成。
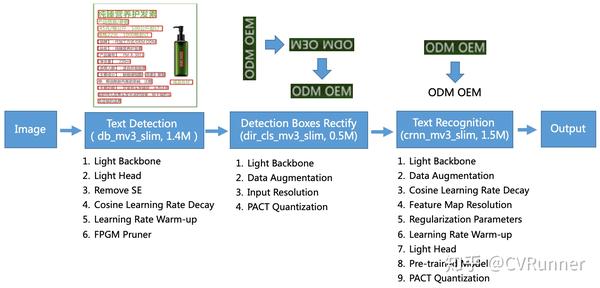
1.文本检测
文本检测的目标是定位出图像中的文字区域,一般希望检测结果是分字段的。PP-OCR采用的是基于分割的DB文本检测算法。使用该方法的出发点是基于分割的文本检测方法,可以得到文本的紧致包围盒。此外,DB的后处理比较简单,方便实际应用。为了进一步提升文本检测器的效果和效率,PP-OCR采用以下6个策略,超轻量骨干网络选择、头部轻量化、SE模块的舍弃、余弦学习率、预热学习率以及使用FPGM模型裁剪器,最终,PP-OCR里面文本检测模型的大小只有1.4M。
2.检测框校准
为了提升检测框中的文字识别效果,保持文字的一致性,一般都希望待识别的文本框是正的水平方向。由于DB的文本检测结果是多边形4点表示,所以很容易将检测结果经过仿射变换,变成水平方向。如果变换后的图像是竖直方向,则旋转90度后,变为水平方向。但是变为水平方向后,文本可能是颠倒的。所以需要一个文本方向分类器判断文本是不是颠倒的。如果实颠倒的文本,转正再识别就可以了。训练一个文本方向分类器是一个基本的图像分类任务。为了进一步提升文本方向分类器的效果和效率,PP-OCR采用以下4个策略,超轻量骨干网络选择,数据增强,增大输入分辨率和PACT int8量化,最终,PP-OCR里面文本分类器模型的大小只有500KB。
3.文本识别
文本识别的目标是将文本行图像转换为文本。PP-OCR采用的是文本识别常用的方法CRNN。虽然CRNN文本识别方法是2016年提出的,有一些历史,但是对于中文识别,是使用最普遍也最有效的文本识别方法。CRNN主要是融合了卷积特征和序列特征,采用CTC损失函数来解决预测标签和真值标签不一致的问题。为了进一步提升文本识别的效果和效率,PP-OCR采用以下9个策略,超轻量骨干网络选择,数据增强,余弦学习率,增大特征图分辨率,正则化参数,预热学习率,头部轻量化,预训练大模型和PACT int8量化,最终,PP-OCR里面中英文文本识别模型的大小只有1.5M。纯英文数字文本识别模型的大小只有900KB。
三、数据
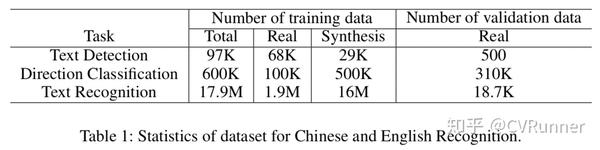
为了实现一个实用的超轻量中英文OCR系统,文中构造了一个大规模的数据集进行模型训练,各个任务的数据统计信息如下表所示。其中合成数据使用的是text_render ( https://github.com/Sanster/text_renderer )
1.文本检测数据
对于文本检测模型的训练,PP-OCR总共使用了9.7万张图像作为训练集,500张图像作为校验集。训练集中的数据,有6.8万张图像来源于真实场景,2.9万张图像来源于合成数据。上述真实场景中的数据,大部分来源于OCR相关的公开数据集,包括LSVT, RCTW-17 , MTWI 2018 , CASIA-10K, SROIE, MLT 2019, BDI, MSRA-TD500 和 CCPD 2019. 还有一部分数据来源于百度图像搜索,通过关键字搜索,获取文档相关的图像。合成图像主要关注的场景有长文本文字的图像,多方向文本的图像和表格图像。
2.方向分类器数据
对于文本方向分类器模型的训练,PP-OCR总共使用了60万张图像作为训练集,31万张图像作为校验集。训练集中的数据,有10万张图像来源于真实场景,其余50万张图像是利用竖直字体合成,并且旋转成水平得到。真实场景数据主要来源于公开数据集 LSVT, RCTW-17 , MTWI 2018。所有校验集图像来源于真实场景。
3.文本识别数据
对于文本识别模型的训练,PP-OCR总共使用了2千万左右的训练数据和1.87万的校验数据。训练集中的数据,有200万张图像来源于真实场景,其余图像都是合成数据。真实场景,部分数据来源于OCR相关的公开数据集,包括LSVT, RCTW-17 , MTWI 2018和CCPD 2019,其余真实图像来源于百度图像搜索。主要是对检测的真值框或者检测结果的图像进行旋转矫正裁剪得到。合成数据主要关注的场景有背景嘈杂,平移,旋转,透视变换,直线扰动,噪声,竖直文字等等。合成数据的语料来源于真实场景图像的语料。所有校验集图像来源于真实场景。
4.OCR系统评估数据
为了验证OCR系统的效果,针对OCR实际应用场景,包括合同,车牌,铭牌,火车票,化验单,表格,证书,街景文字,名片,数码显示屏等,收集了300张图像作为评估集合。每张图平均有17个文本框,下图给出了一些图像示例。

5.多语言数据
为了验证PP-OCR对于非中英文数据的识别能力,收集了一些英文数字、法语、韩语、日语和德语的语料,合成了一些文本行图像,用于训练相应的文本识别模型。由于MLT 2019是包含多语言的文本图像,因此中英文OCR系统中的文本检测模型可以同时支持多语言文本检测。
------------------------------------------------------------------------------
感谢大家关注,PP-OCR: 3.5M超轻量中英文OCR模型详解系列总共有4个部分,列表如下:
(一) 简介、方案概览和数据
(二) 文本检测优化瘦身
(三) 文本方向分类器优化瘦身
(四) 文本识别优化瘦身
欢迎大家star PaddleOCR(https://github.com/PaddlePaddle/PaddleOCR),支持该repo的建设。感兴趣的朋友,可以加入Repo里面的PaddleOCR技术交流微信群,一起讨论OCR相关问题。
录1应用介绍2支持版本1应用介绍麻将狂热是一个简单的、单人,瓷砖匹配的游戏。比赛的目的是消除所有的瓦片从董事会通过配对它们与类似的。你只能选择瓷砖博彩问答,至少有一方(左或右)免费配对。 Mahjong Mania is a simple, single-player, tile-matching game. The objective of the game is to remove all the tiles from the board by pairing them with similar ones. You can only select tiles which have at least one side (left or right) free for pairing.




